Performance
Executive Summary
We benchmarked MetaFFI against dedicated native packages (JNI, CPython, JPype, Jep, ctypes) and gRPC across all 6 language pairs, with 11 scenarios each — 198 benchmarks total, all passed.
Key finding: MetaFFI delivers near-native FFI performance with dramatically less code — one language, half the SLOC, and lower complexity than writing dedicated bridge code.
Code Complexity Comparison
MetaFFI requires significantly less code and fewer languages to achieve the same cross-language integration:
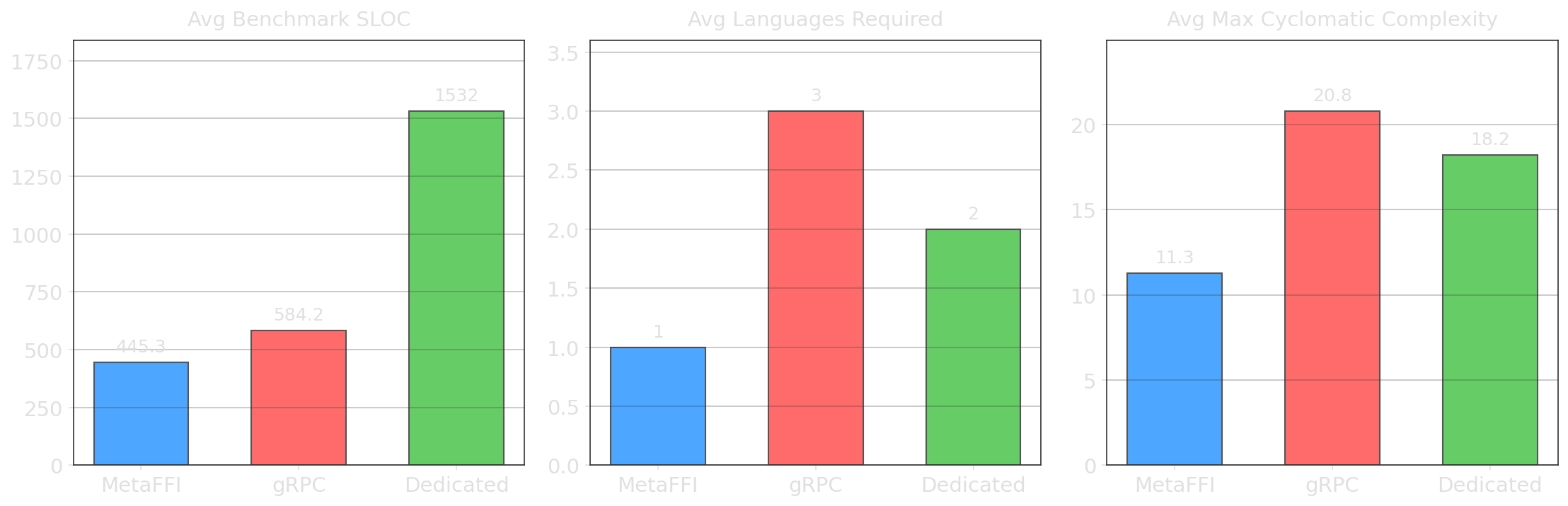
| Metric | MetaFFI | Dedicated (native) | gRPC |
|---|---|---|---|
| Avg benchmark SLOC | 445 | 1,532 | 584 |
| Languages required | 1 | 2 | 3 |
| Avg max cyclomatic complexity | 11 | 18 | 21 |
With MetaFFI, you write host code in one language only. Dedicated packages (JNI, CPython, etc.) require your host language plus low-level C/C++ bridge code. gRPC requires your host language plus protobuf definitions plus the guest language service implementation.
MetaFFI vs Dedicated Packages
MetaFFI is not the fastest option — dedicated native packages like JNI, CPython API, and JPype are faster because they are hand-tuned, low-level bridges with no abstraction layer.
However, dedicated packages:
- Require writing C/C++ bridge code or learning complex APIs (JNI, CPython)
- Are specific to a single language pair
- Have steep learning curves and fragile build configurations
MetaFFI trades some performance for a dramatically simpler developer experience: load a module, call a function. For most applications, the microsecond-level overhead is negligible compared to the actual work being done.
Cross-Pair Latency Summary
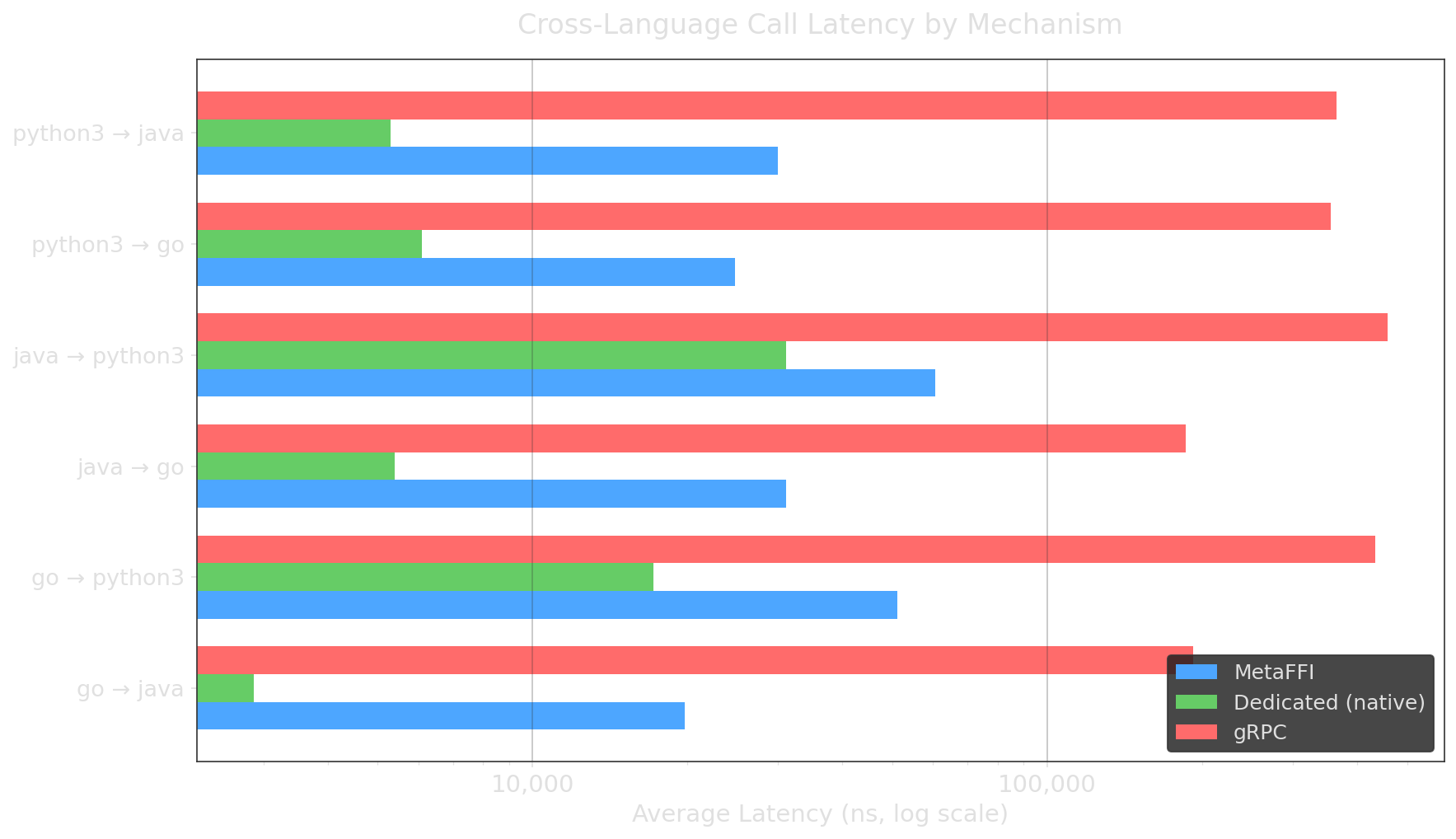
Detailed Numbers
| Language Pair | MetaFFI (ns) | Dedicated (ns) | gRPC (ns) | MetaFFI vs Dedicated |
|---|---|---|---|---|
| Go → Java | 19,769 | 2,867 (JNI) | 191,936 | 6.9x slower |
| Go → Python3 | 51,093 | 17,134 (CPython) | 434,129 | 3.0x slower |
| Java → Go | 31,092 | 5,394 (JNI) | 185,655 | 5.8x slower |
| Java → Python3 | 60,619 | 31,029 (Jep) | 457,936 | 2.0x slower |
| Python3 → Go | 24,687 | 6,083 (ctypes) | 355,969 | 4.1x slower |
| Python3 → Java | 29,946 | 5,289 (JPype) | 364,973 | 5.7x slower |
Values are averages across 11 benchmark scenarios per pair (void call, primitives, strings, arrays, objects, callbacks, dynamic typing, 10k arrays).
The overhead comes from MetaFFI’s abstraction layer — the same layer that lets you skip writing JNI headers, CPython reference counting, or cgo build rules. For most workloads the actual computation dwarfs the call overhead.
What About gRPC?
Some teams repurpose gRPC for in-process cross-language calls. Since gRPC is designed for distributed systems, it adds serialization, network, and server overhead that isn’t needed for in-process use. MetaFFI is purpose-built for in-process calls.
| MetaFFI | gRPC | |
|---|---|---|
| Communication | In-process function calls | Network socket (loopback) |
| Data transfer | Shared memory via CDTs | Serialization (protobuf) |
| Infrastructure | None | Server process + client stub |
| Latency | Microseconds | Milliseconds |
MetaFFI is 6-14x faster than gRPC across all language pairs:
| Language Pair | MetaFFI (ns) | gRPC (ns) | Speedup |
|---|---|---|---|
| Go → Java | 19,769 | 191,936 | 9.7x faster |
| Go → Python3 | 51,093 | 434,129 | 8.5x faster |
| Java → Go | 31,092 | 185,655 | 6.0x faster |
| Java → Python3 | 60,619 | 457,936 | 7.6x faster |
| Python3 → Go | 24,687 | 355,969 | 14.4x faster |
| Python3 → Java | 29,946 | 364,973 | 12.2x faster |
Benchmark Scenarios
Each language pair was tested across 11 scenarios:
| Scenario | Description |
|---|---|
void_call |
Empty call (no parameters, no return) — measures pure overhead |
pass_primitive |
Pass and return a single integer |
pass_string |
Pass and return a string |
pass_array |
Pass and return a small array |
pass_object |
Create an object, call methods on it |
object_method |
Call a method on an existing object instance |
callback |
Pass a host function to guest code and have it called back |
dynamic_type |
Pass/return values using any/interface{} types |
pass_10k_array |
Pass a 10,000-element array |
return_10k_array |
Return a 10,000-element array |
dynamic_10k |
Pass 10,000-element array as dynamic type |
Methodology
- Each benchmark runs configurable warmup and measurement iterations (default: 100 warmup, 1000 measured)
- Outliers removed using IQR method (1.5x interquartile range)
- Statistics computed: mean, median, standard deviation, min, max, p95, p99
- All benchmarks run on the same machine in sequence
- Environment: Windows 11, Go 1.23, OpenJDK 22, Python 3.11
Note on generated stubs: The host compiler generates thin wrapper functions that call the same MetaFFI runtime. Using generated stubs does not change runtime overhead — it changes developer experience only. The benchmarks above apply equally to both dynamic loading and generated stub modes.
For full details, see the MetaFFI paper.